A few people asked me recently why some of us are using the hashtag #cloudlife and what it means. This came out of the Ahead Tech Summit presentation I was preparing for and worked with Nick Rodriguez on in June. I was explaining to Nick my concept and he created this great image.
So what does it mean?
Ultimately, it comes from a belief that Cloud is about creating a true experience. This means not just changing the way customers of IT consume services via a catalog, but going that extra mile.
I’ll get on to roles and more Cloud Design topics in a future post .The one thing I want to stress over and over is that our goal in creating a Cloud is to create this place people come to for IT services and leave feeling like they got something more.
If you’re an IT person, you must put yourself in the developers shoes and try to think of the pain and annoyance they actually go through when submitting a form. They wait weeks for their server to come and they then still have to go to subsequent teams to get various pieces of software installed such as: DR options approved, extra storage and so on. Then, they have to make sure that everything they did in Dev works in QA and finally Production. A sysadmin might push a patch out or a VM template that doesn’t work as it did the previous month because someone else made a change.
Follow this up with the sheer amount of Public Cloud PaaS services and other external services the teams wish to consume. Many of these services require security approvals and perhaps additional firewall and networking configurations.
It all adds up to a frustrated customer and in turn ultimately affects the businesses ability to innovate and grow.

The opposite is the #cloudlife experience..
Happy Customer A: “Wow, I came to this catalog and got everything I needed. BAM! Now I can create something awesome today while my idea is hot.”
Happy Customer B: “This Cloud is better than just the AWS or Microsoft Cloud. I get those features and more. Everything I want is here!”
Happy Customer C: “I think…I love this Cloud… #cloudlife”
Happy Customer D: “If I had a Cloud, it would be just like this cloud. I’m telling my friends about DevOps and #cloudlife.”

It’s not about just having the best programmer and engineering the best back end services but the full end to end experience. How you design the front end menu, how you guide every decision the user makes, and how you can get them what they need to be successful and grow the business are front and center. It takes a combination of people and skills to execute on this successfully.
What does it mean in practice?
Take an example of a Developer that has deployed an environment of SugarCRM, an Open Source CRM tool. Great they deployed it from their request catalog but what if they want to synchronize data from one environment to another for testing? Previously, they would have had to put in a request for someone to backup and restore the database to the new environment. This could then involve a piece of paper being handed around between teams until the task is completed.
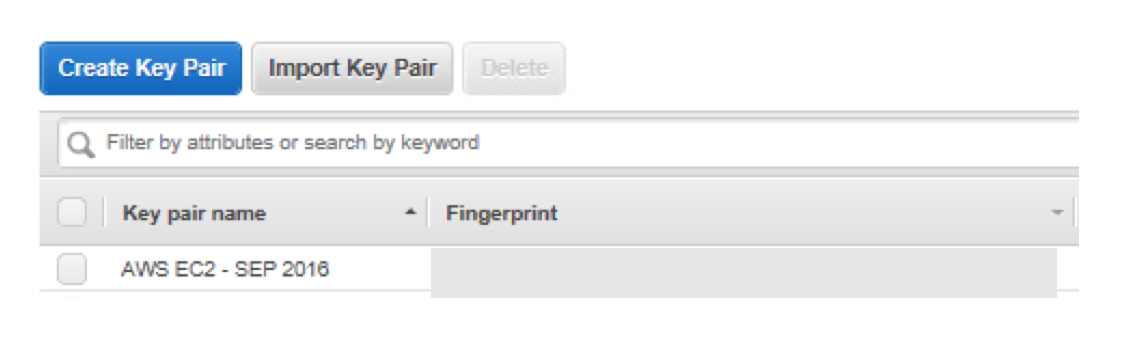
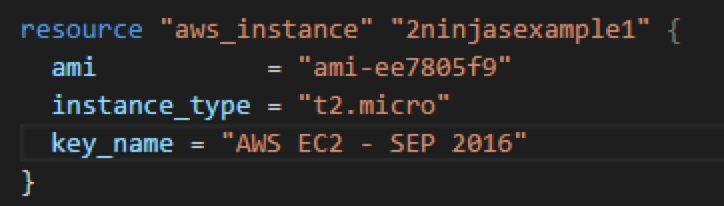
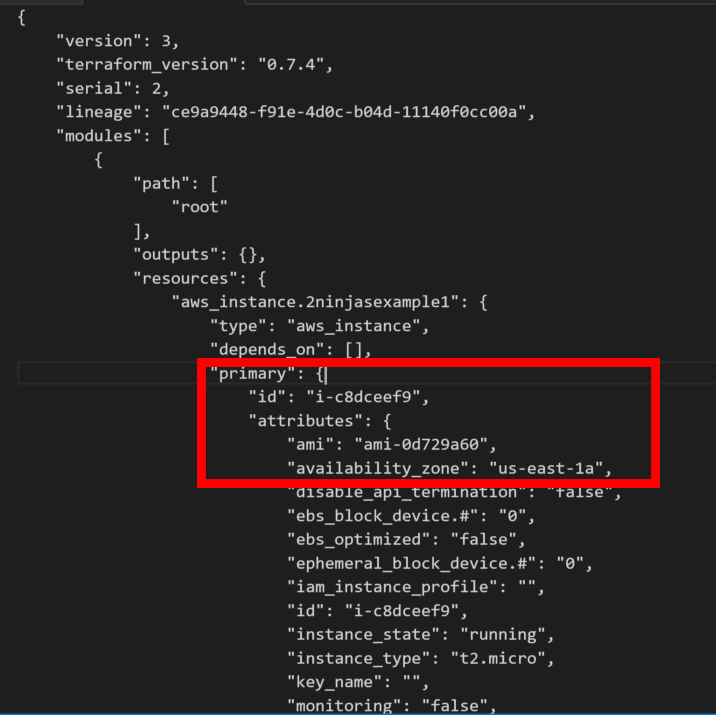
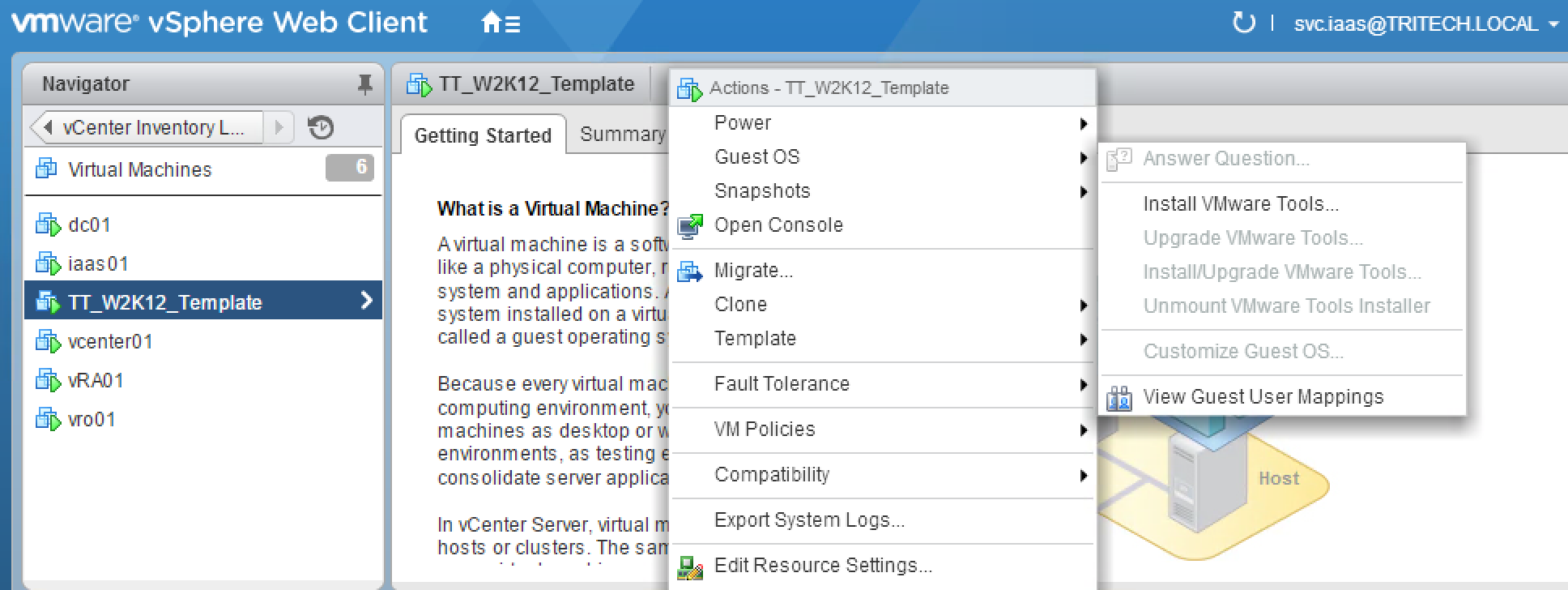
The alternative is an option like the screenshot below in vRealize Automation. We add an Action which is visible in the items list that gives them the ability to execute this operation with one click.

Clicking the “vRA-DevOpsTeamX-SyncData” Button initiates a vRealize Orchestrator workflow. This workflow in turn connects to a Tintri Storage Array to initiate a Sync VM. The workflow will create all the appropriate change controls, shutting down of VMs, storage array tasks etc. Again, think of everything that you need to do to complete the task and provide it as a self service option.
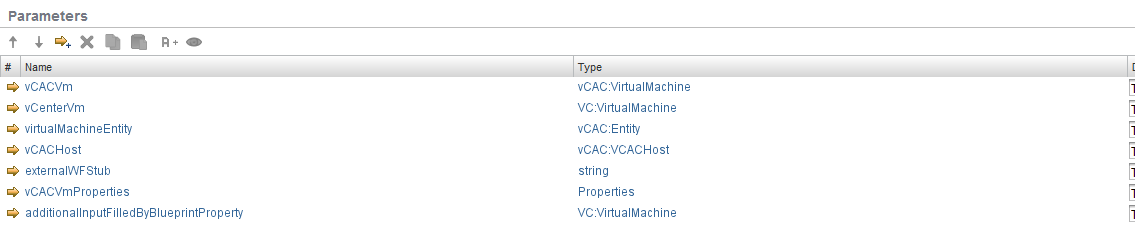
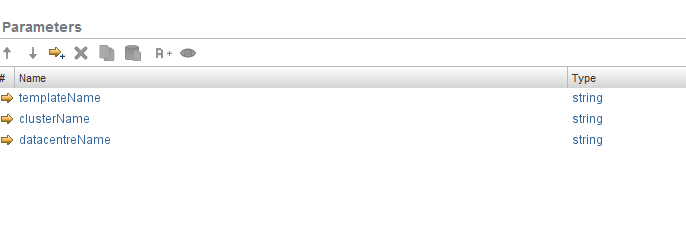
Essentially, the workflow would look something like this:

Other Examples…
Time permitting, some of these will turn into blog posts as well, but here are some examples of clear services you can offer to make peoples lives easier.
- Complex Environment Deployments (IaaS, PaaS, SaaS mixes)
- This means getting everything they need. Not just a VM deployed.
- Event Based Orchestration – e.g. AWS Lambda to SNOW, Orchestration systems etc.
- Automated Redeployment of Environments on Schedule
- Self Service Disaster Recovery CheckBox
- Self Service Backups and Restores
- Business Discovery Mapping via Parent/Child Relationships created in blueprints
- Automated Service Account creation and deletion
- Automated Snapshots before Patching of Systems
- Automated Firewall Rule creation and deletion
These are just a handful of ideas. Remember, with each one, we’re taking out the additional paperwork by automating the tasks you’d typically do in your ITIL tool like ServiceNow.
What is #cloudlife…?
It’s certainly also become a #hashtag we use whenever we are working on Cloudy stuff (e.g. creating a cloud proposal while in the dentist chair…wasn’t me) or thinking about a new innovative Cloud idea while drinking a Tim Carr Starbucks Iced Green Tea (#notpropertea). Essentially, it’s a way of thinking beyond our Infrastructure roles and what the requester is asking for to create something more.
#cloudlife is about reaching for the best possible user experience. One that doesn’t feel like it’s forcing you into a box but instead feels refreshing end enjoyable.