

Before diving into the other AWS services, it is highly recommended that you gather a strong background in all of the AWS Storage services and their specific use cases. In this post, we will be discussing AWS S3 specifically.
In short, S3 provides highly scalable object storage. In 2013, Jeff Barr , wrote a blog which stated that Amazon S3 had reached over 2 trillion objects and there were 1.1 million requests a second. I’d love to find an updated stat but this in itself gives an indication of how widely used this service is already.
Object Storage – Quick Primer
For anyone not familiar, object storage provides the ability to store objects (obvious I know). These are essentially collections of digital bits. This could be a document, digital photo, xml file etc. Object storage offers highly reliable and easy scalable storage of all these digital bits but there is basically no structure at all. It simply provides storage and differs from file storage which provides additional functionality. An example is something like update functionality. In a typical file system, you can append information directly to a file. In object storage, this is not the case. You can add an object and retrieve it immediately but you can’t change it. Rather, you have to update the object and then reinsert it. You can still apply permissions and versioning as we will see soon but as you architect applications today, you need to consider whether or not you truly do need a file system. Amazon did recently release EFS (think NAS basically) and this can potentially satisfy your specific file use cases. It is still early on though and the verdict is still out.
How do I use it? – Creating our first S3 Bucket
First login to your AWS console and you will see on the left hand side under “Storage & Content Delivery” the icon for S3.

You will be presented with the welcome screen to S3

The first thing to note is the term “Bucket”. It helps to think of a bucket basically as a folder but the name of the bucket is globally unique. Once someone takes the bucket name, it is not available for anyone else to use.
Simply select Create Bucket and type in a name for your new S3 bucket.
If someone else has the name already, it will error out and let you know. The name of the bucket also needs to be in lowercase.
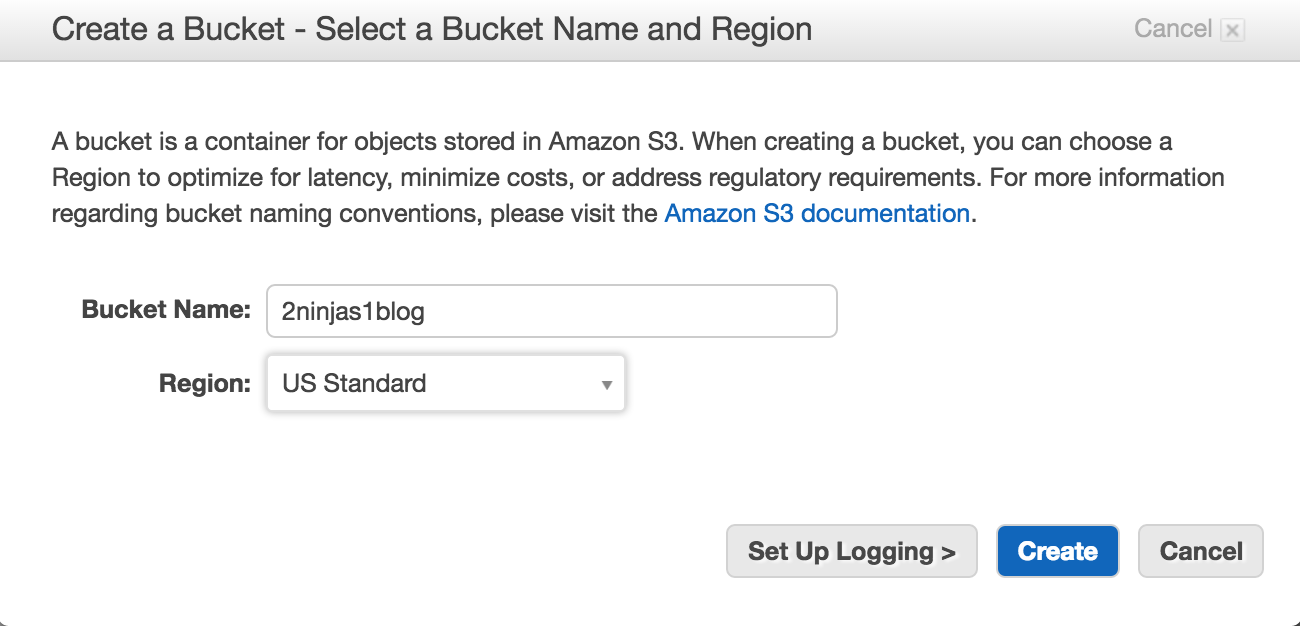
Once created, you will see the main S3 management screen.
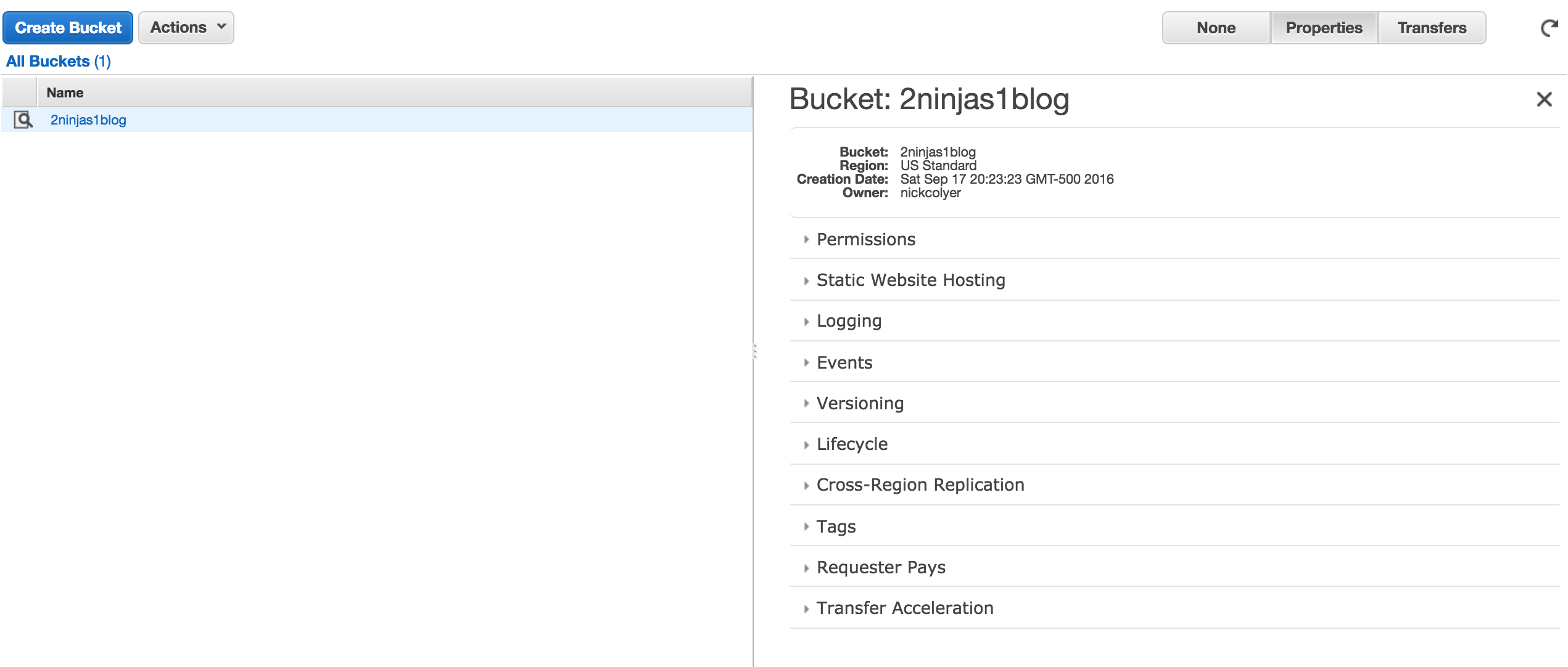
You can see on the right hand side a number of options which we will come back to in subsequent posts. For now, if we click into our bucket, we will see that it is empty.

We can create additional folders inside of our bucket or simply begin to upload files at this point. If you select the Actions menu, you will also see additional options.
Let’s go ahead and upload a file. In my example, I will simply select a PNG image file as per the screenshot below.
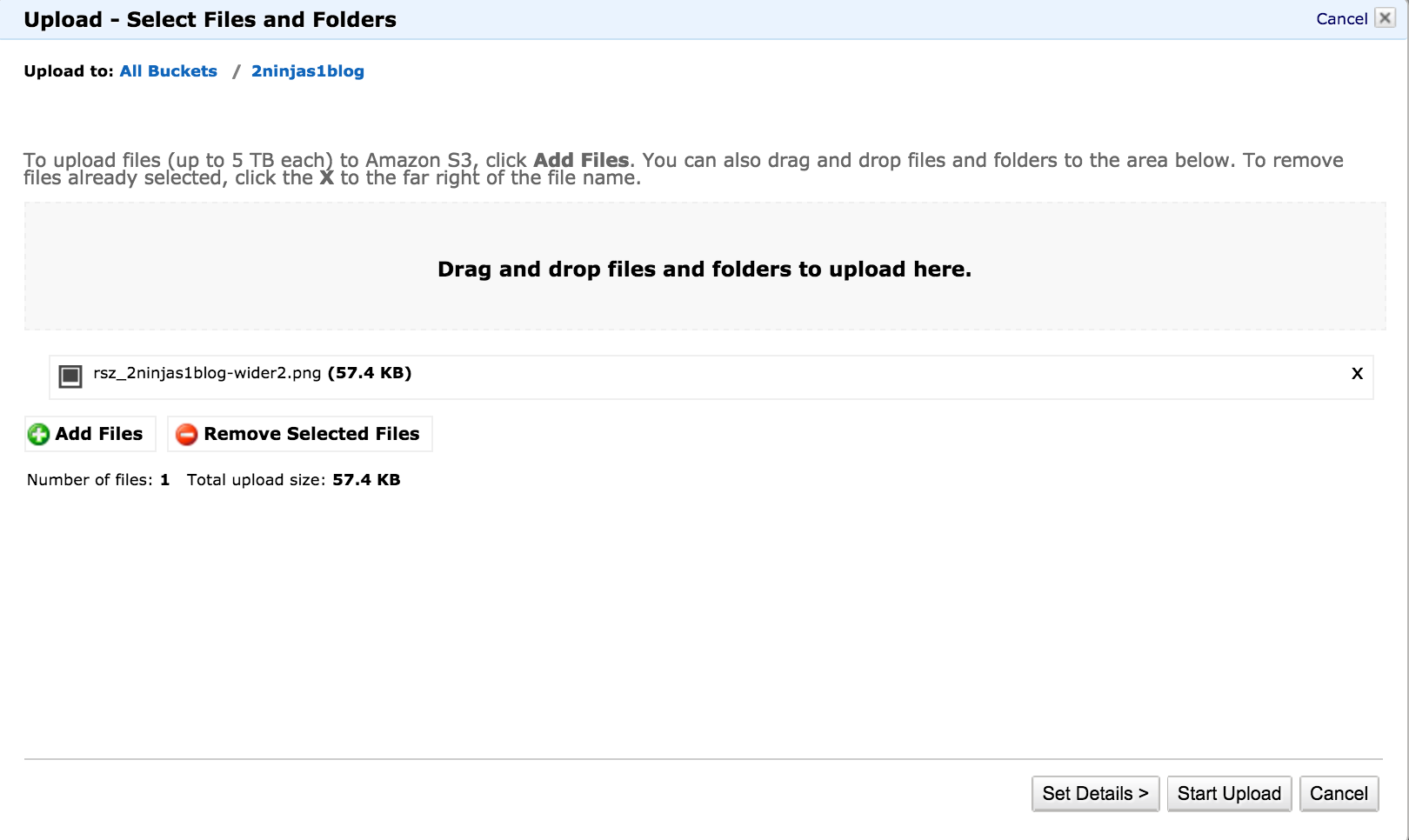
Before we go ahead and start the upload it is worth clicking the Set Details button.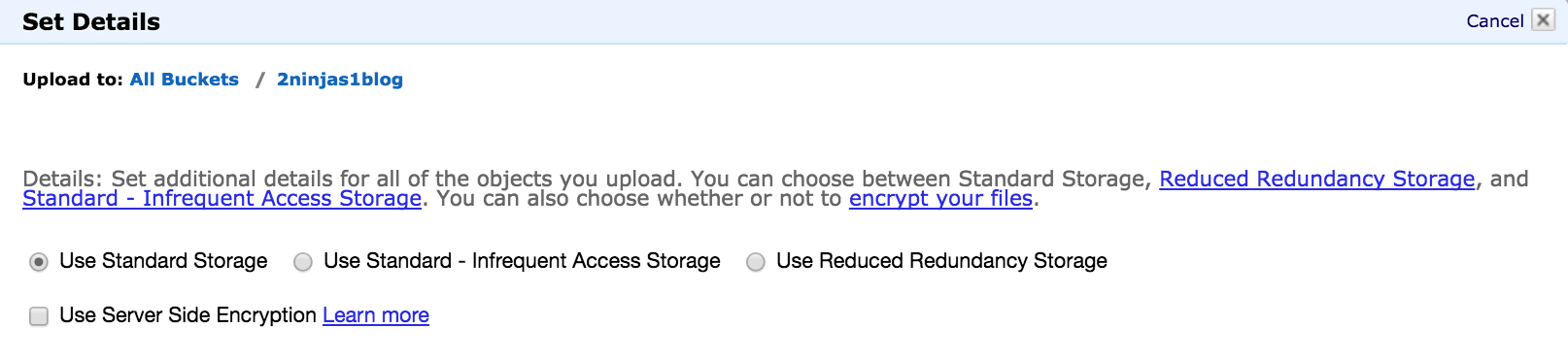
You can see here that we have additional storage options we can apply. For now, we are going to select Use Standard Storage but there are ways to further reduce cost if the other storage options apply. There is also an option to use Server Side Encryption.
Go back and select Start Upload.

Once completed, we will see our image file appear on the left hand side.
Select Properties from the menu on the top right, and you will be able to see

Note the link. If I put this into my web browser directly, I get the following Access Denied error.
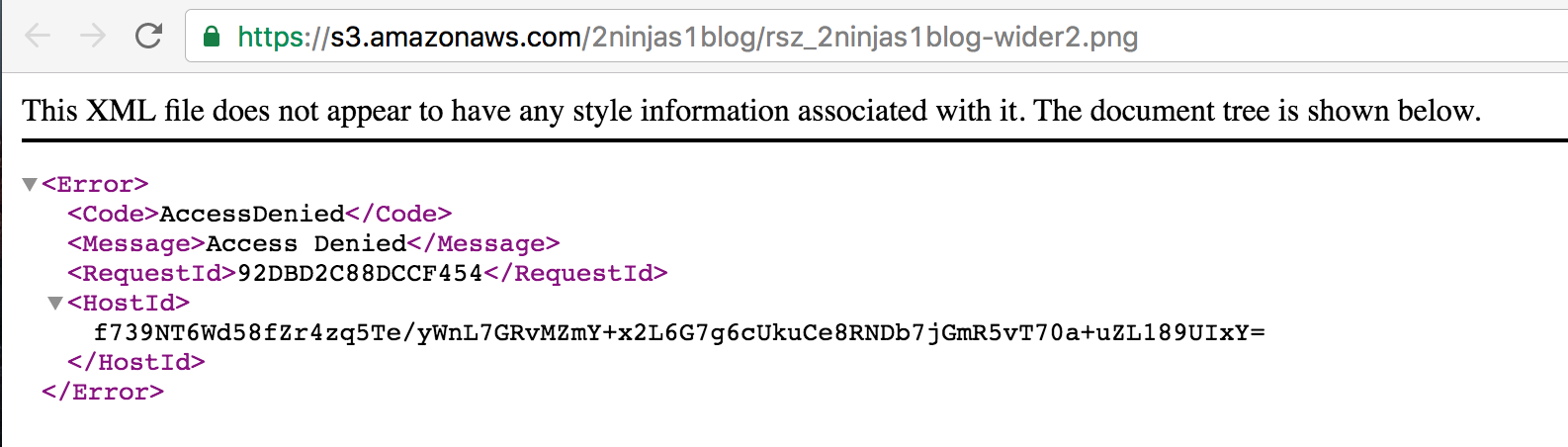
This is because the permissions are not set to allow public access. If I go ahead and add Everyone to have Open/Download permissions as follows…

…I end up now being able to access this image publicly.

With that, our basic primer comes to an end. In the next post we will discuss the different storage types and permissions we saw above.