The post It’s ON with Turbonomic and vRO appeared first on 2ninjas1blog.com.
]]>Below is the schema for vRA workflow:

First is a scriptable task to gather inputs for vRA. The inputs are all vRA specific so I could remove these. At the end it, the workflow is pushing back properties to vRA so I removed “Override vRA Settings” at the end.
Inputs removed from original VMTurbo Main workflow:
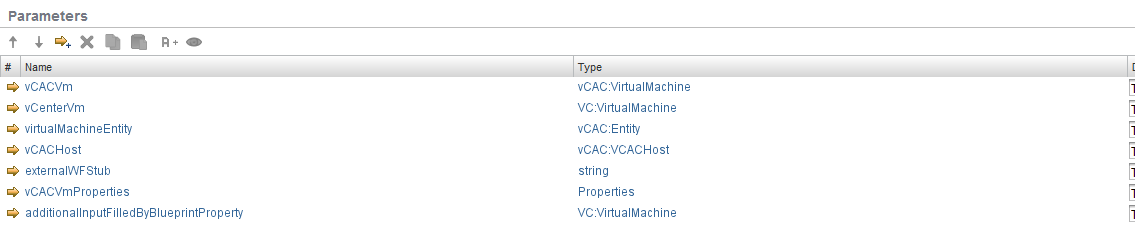
My workflow ended up like this, removing vRA dependencies and ending with 2 scriptable tasks to convert the datastore and host to VC:objects instead of strings. These scripts will be covered in another post.

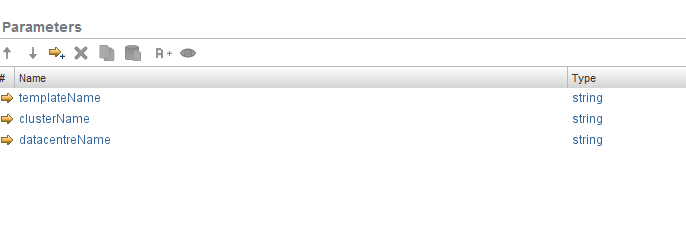
My inputs end up moving from general attributes and are templateName, clusterName and datacentreName. In the future I will likely add a scriptable task at the beginning of the workflow to determine these as they will come from inputs generated by my Windows or Linux Master Build workflow.
Inputs converted from attributes:
I also now have outputs for the actual VC: Datastore VC: Host System objects for your clone workflow in vRO. These were created via the scriptable tasks which take the strings returned from Turbonomic and do a lookup to match them to the vCenter objects.
Outputs created:

What’s great about having this functionality from Turbonomic is now the best host and the best datastore will be selected based on analytics from Operations Manager. I originally was picking my datastore based on amount of free space but now using the REST API I can have the least utilized host and datastore supplied to by clone workflow.
Download the modified workflows here.
I’ll be going over these workflows in the upcoming webinar “Overcoming Private Cloud Challenges in Healthcare IT”, September 29th at 2:00PM EST. Register here
The post It’s ON with Turbonomic and vRO appeared first on 2ninjas1blog.com.
]]>